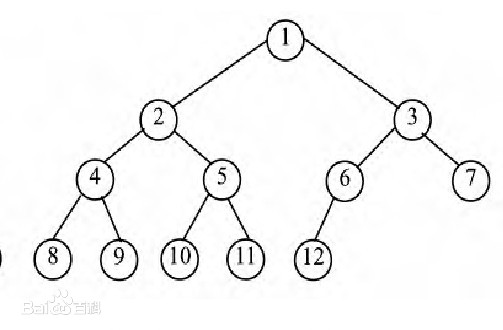
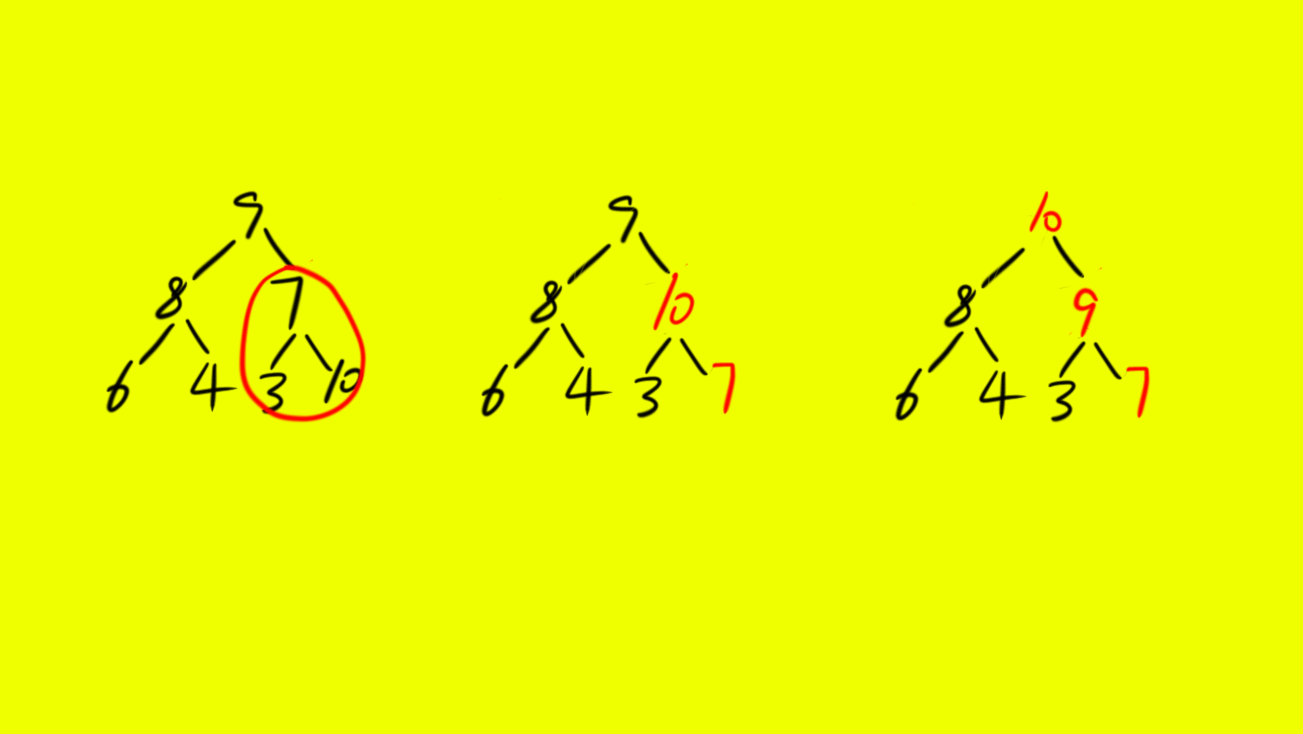
functionsift(arr:number[], low:number, high:number){// 设空位置为ilet i = low;// j代表i的子节点中较大的那个节点的索引位置let j =2* i +1;const tmp = arr[i];// 当j索引没有越界while(j <= high){// j+1也没有越界,判断右孩子是否比左孩子大,如果右孩子大那么就将右孩子索引赋值给j// 重述:j代表的是i的两个孩子中较大的那个节点的索引if(j +1<= high && arr[j +1]> arr[j]){
j = j +1;}// 当较大位置的值大于空位置的值if(arr[j]> tmp){// 将更大的值赋值到空位置
arr[i]= arr[j];// 空位置变成当前j的位置
i = j;// j还是存的当前空位置的两个孩子中较大的那个,此时存的左孩子,// 下一次循环就会变成左右两个孩子中较大的那个位置索引
j =2* i +1;}else{// 如果较大的孩子的值小于或等于空位置的值那么就不需要进行调整直接退出break;}}// 调整结束后空位置的值就变成最初的位置的值
arr[i]= tmp;}functionsift(arr:number[], low:number, high:number){// 设空位置为ilet i = low;// j代表i的子节点中较大的那个节点的索引位置let j =2* i +1;// 当j索引没有越界while(j <= high){// j+1也没有越界,判断右孩子是否比左孩子大,如果右孩子大那么就将右孩子索引赋值给j// 重述:j代表的是i的两个孩子中较大的那个节点的索引if(j +1<= high && arr[j +1]> arr[j]){
j = j +1;}// 当较大位置的值大于空位置的值, 下次循环的i的值是本次循环j的值if(arr[j]> arr[i]){// 交换空位置与较大的位置的值[arr[j], arr[i]]=[arr[i], arr[j]];// 空位置变成当前j的位置
i = j;// j还是存的当前空位置的两个孩子中较大的那个,此时存的左孩子,// 下一次循环就会变成左右两个孩子中较大的那个位置索引
j =2* i +1;}else{// 如果较大的孩子的值小于或等于空位置的值那么就不需要进行调整直接退出break;}}}
构造如下:
functionheap(arr:number[]){const high = arr.length -1;// 构造堆 农村包围城市 -> 从最后一个非叶子节点开始挨个调整构造,一直到整个堆for(let i =(high -1)>>1; i >=0; i--){sift(arr, i, high);}return heap;}